CDOs (i.e. Collateralized Debt Obligation) are a type of asset-backed security and structured credit product constructed from a portfolio of fixed-income assets. Essentially a CDO is a corporate entity constructed to hold assets as collateral and to sell packages of cash flows to investors. More specifically, synthetic-CDOs do not own cash assets like bonds or loans. Instead, they gain credit exposure to a portfolio through the use of credit default swaps, a derivative instrument. Without going into the detailed mechanisms of sCDO trading, we can say that the correct pricing of CDOs is extremely important as wrong risk assessment and identification can easily result in huge losses.
Generally speaking, the CDO pricing problem is solved as soon as the loss distribution of the reference portfolio (its tranches) can be calculated. However, to do so one has to build highly complex models which exactly match the peculiarities of each sCDO in question. The complexity of these models derives from the fact that credit defaults should be estimated for each and all of the many assets in the portfolio, which implies taking into account possible interdependencies between them. Besides, the timing of such defaults should also be estimated. As a result, pricing a single portfolio implies estimating a large number of joint probability distributions and projecting them in the time. Moreover, Monte Carlo methods are used in order to extract some variability values concerning the portfolio price, implying a huge amount of successive pricings for a single portfolio.
As a result, our solution consists in accelerating the computation time of sCDO prices, and thus improving the existing solution over the time axis, while enabling at the same time the user to choose the level of accuracy of the results. Note also that to meet this later constraint, the results generated by our hardware implementation have to be as precise as the ones given by a standard software method and therefore, our system uses floating point operations even if it is not very common and quite costly in terms of resources to implement them directly on FPGAs.
Hardware platform
The development hardware platform consists in the PEV1100 board, shown in the figure, proposed by
IOxOS and initially designed with the aim of upgrading existing data acquisition and control systems together with the TOSCA FPGA design kit.

The PEV1100 is connected to a standard computer using a PCIe external cabling solution and is thus organized around a 6-port PCIe x4 switch working with 1Gbyte/s full duplex data transfer rate and supporting transparent memory mapped transactions among the following elements: the local host, two PMC or XMC slots, a VME64x bus, an on-board shared memory tightly coupled with embedded multi-channel intelligent DMA controller and a FPGA user area for customized applications. Additionally, the PEV1100 implements an event distribution engine providing the mechanisms for Interrupt dispatching and a 4-channel intelligent DMA controller designed to efficiently support the PCIe communication protocol through multiple outstanding R/W transactions, i.e. it is optimized for long burst transactions.
In this project, we specifically used the PCIe connection to the host computer to transfer data to and from the on-board shared memory, while the FPGA customizable user area executes the actual computation, i.e. accelerates the sCDO pricing algorithm. In the prototype board, the shared memory consists in 1Gb of DDR2 RAM and possesses 64 direct low-latency links with the user area. This latter consists in a Virtex5 SX50T FPGA, which is optimized for DSP and memory-intensive applications and integrates enhanced DSP blocks for parallel processing with a big memory-to-logic ratio. Note that, for scalability reasons, the PCIe interface is implemented in the FPGA itself, thus leaving about 80% of its resources available for our dedicated sCDO pricing accelerator.
Algorithm & top level architecture
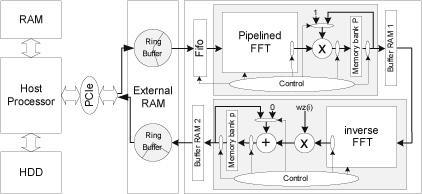
The basic principle of sCDO pricing consists of estimating the joint probability of defaults among many different credits. Usually, estimating such joint probabilities requires the computation of convolutions among vectors representing the different default probabilities for the credits. Nevertheless, as the number of credits can be quite high in the portfolios, instead of using a simple convolution process to obtain the loss distribution (joint probability distribution) of the different credits, we use a multiplication in the ``frequency'' domain that requires less computational time.
As a result, the algorithm uses a Fast Fourier Transform (FFT) in order to reach the ``frequency'' domain where the multiplication takes place. After this step, an inverse FFT is used to convert the result back in the ``time'' domain in order to get the joint probability distribution. (Note that some other algorithmic steps are involved in the sCDO calculation, for example to smooth the resulting values conditionally to different market factors.) A careful study of the algorithm then gave us the top level architecture for our acceleration system that is shown in the figure.
Results
In the framework of this project, we finally have presented a working hardware implementation of a sCDO pricing algorithm accelerating the computation up to 14 times as compared to a software based solution. This implementation has been realized on the development board PEV1100 embedding a Virtex5 SX50T FPGA running at 200 Mhz. The speedup has been obtained by the efficient utilization of the pipelining technique at several levels (computing blocks, FFT stages and basic floating point calculations).
The use of the PCIe communication protocol allows our system to be easily extended using multiple FPGAs or even multiple computation boards, i.e. in dispatching the calculation of different sCDOs on several computing modules to increase the total speedup. The algorithm is especially well suited to this capability, as the amount of transferred data remains quite low compared to the amount of computation executed. This feature would allow the system to be easily adapted to integrate more than 200 computing modules, without even reaching the limit of the communication bandwidth.
With a targeted final system being currently developed by
IOxOS, by simply replicating our design in the eight Virtex-6 240T that will likely compose the platform, as each of these FPGAs contains almost four time the computational resources of the Virtex-5 SX50T and will be able to run at a higher frequency, we expect to obtain a speedup of about 650 for a precision of the credit pricing implying the use of 1024 points FFTs. Moreover our system allows this speedup to be reached with a huge spare in the buying and operating costs with respect to a standard software based solution.
Consequently, we can state that the FastPricer CTI project completely full filed its goals:
- the prototype implementation has been successfully realized
demonstrating the capabilities of the development board and design tool
kit provided by the IOxOS company
- it has been demonstrated that our solution could really improve the
calculation time of sCDO with respect to software implementations, and
that with a much lower operating cost
- it has been proven that our system could be integrated within the running work flow of the RiskMetrics company
- the necessary adaptations for our system to be implementable in a
market sized way and efficiently used in real production have been
defined